for key, value in indexDict.items(): # 该文件夹下的所有文件(以便日期排序) file_paths = [] # 要遍历的文件夹路径 folder_path = "./source/_posts/" + value # 打开文件,准备写入绝对路径的文件 index_file_path = "./source/index/" + key + "/index.md"
withopen(index_file_path, "r") as r_file: lines = r_file.readlines()
withopen(index_file_path, "w") as w_file: for i inrange(0, 6): w_file.write(lines[i])
# 遍历文件夹下的所有文件 for root, dirs, files in os.walk(folder_path): dirs.sort() for file_name insorted(files): file_path = os.path.join(root, file_name) if file_path.endswith(".md"): file_paths.append(file_path)
last_head_weight = 0 last_parent = "" # 头部索引的列表,用于排序和暂存 headerList = [] for path in file_paths: curr_head_weight, curr_parent = folderParser(path) headMkd = head(curr_parent, curr_head_weight) ifnot curr_head_weight == last_head_weight: # 标题级别不等 headWritter(headerList, w_file) w_file.write(headMkd) print(headMkd, "has been written to", index_file_path, "\n") headerList = [] elifnot last_parent == curr_parent: # 标题级别等但是标题内容不等 headWritter(headerList, w_file) w_file.write(headMkd) print(headMkd, "has been written to", index_file_path, "\n") headerList = [] last_head_weight = curr_head_weight last_parent = curr_parent withopen(path, "r") as file: lines = file.readlines()[0:15] headDict = {"relpath" : path.split("_posts")[-1].replace(".md", "").strip(), "path" : path} for line in lines: if line.strip().startswith("hidden"): headDict["hidden"] = line.replace("hidden:", "").strip() if line.strip().startswith("description"): headDict["description"] = line.replace("description:", "").strip() if line.strip().startswith("cover"): headDict["cover"] = line.replace("cover:", "").strip() if line.strip().startswith("title"): headDict["title"] = line.replace("title:", "").strip() if line.strip().startswith("date"): headDict["date"] = line.replace("date:", "").strip() # 特殊情况处理 ifnot"description"in headDict or headDict["description"] == ""or headDict["description"] == "null": headDict["description"] = "description" ifnot"hidden"in headDict or headDict["hidden"] == ""or headDict["hidden"] == "null": headDict["hidden"] = "false" ifnot"cover"in headDict or headDict["cover"] == ""or headDict["cover"] == "null"or headDict["cover"].startswith("'linear-gradient"): headDict["cover"] = randCover(headDict["date"])
if headDict["hidden"] == "false": headerList.append(headDict) headWritter(headerList, w_file)
elif [ "$input" = "new" ]; then cd ~/blogs/source/_posts read -p "Present working dir: $(pwd), sure to continue?y/n" continueNew if [ "$continueNew" = "n" ]; then echo"Bye!" else hexo new -p "$filename" echo"____" echo"$filename" rmdir"$(pwd)/$filename" fi
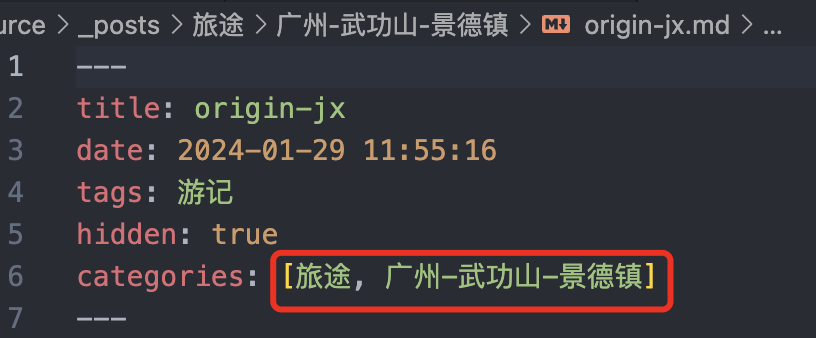
# 遍历_posts目录及其子目录下的所有文件 for root, _, files in os.walk(posts_dir): for file in files: file_path = os.path.join(root, file) # 计算当前文件相对于_posts目录的路径 rel_path = os.path.relpath(file_path, start=posts_dir_abs) rel_path = rel_path[:rel_path.rfind('/')].replace("/", ", ") rel_path = "categories: [" + rel_path + "]" withopen(file_path, 'r') as file: lines = file.readlines()
index = 0 catindex = 0 withopen(file_path, 'w') as file: for line in lines: index += 1 if line.strip().startswith("categories:"): file.write(rel_path + "\n") catindex = index else: file.write(line) print(rel_path, "has been written to", file_path, "line:", catindex)
for key, value in indexDict.items(): # 该文件夹下的所有文件(以便日期排序) file_paths = [] # 头部索引的列表,用于排序 headerList = [] # 要遍历的文件夹路径 folder_path = "./source/_posts/" + value # 打开文件,准备写入绝对路径的文件 index_file_path = "./source/index/" + key + "/index.md"
# 遍历文件夹下的所有文件 for root, _, files in os.walk(folder_path): for file_name in files: file_path = os.path.join(root, file_name) file_paths.append(file_path)
for path in file_paths: withopen(path, "r") as file: lines = file.readlines()[0:10] headDict = {"relpath" : path.split("_posts")[-1].replace(".md", "").strip(), "path" : path} for line in lines: if line.strip().startswith("hidden"): headDict["hidden"] = line.replace("hidden:", "").strip() if line.strip().startswith("description"): headDict["description"] = line.replace("description:", "").strip() if line.strip().startswith("cover"): headDict["cover"] = line.replace("cover:", "").strip() if line.strip().startswith("title"): headDict["title"] = line.replace("title:", "").strip() if line.strip().startswith("date"): headDict["date"] = line.replace("date:", "").strip() # 特殊情况处理 ifnot"description"in headDict or headDict["description"] == ""or headDict["description"] == "null": headDict["description"] = "description" ifnot"hidden"in headDict or headDict["hidden"] == ""or headDict["hidden"] == "null": headDict["hidden"] = "false" ifnot"cover"in headDict or headDict["cover"] == ""or headDict["cover"] == "null"or headDict["cover"].startswith("'linear-gradient"): headDict["cover"] = randCover()
if headDict["hidden"] == "false": headerList.append(headDict)


 微信
微信 支付宝
支付宝